Home / Our thinking / Insights /

Table of contents
At the 2026 NashTech Connect Conference, AI expert David Thorley led a breakout session for technology leaders on a topic that rarely gets honest airtime: AI model failure. This article distils the key insights for CIOs and CTOs responsible for turning AI ambition into measurable business outcomes.
AI models fail
AI models can fail and often do. Across industries, we repeatedly see the same pattern: impressive demos, enthusiastic pilots and then quiet abandonment once the real‑world limitations surface. In fact, research* from organisations such as MIT, McKinsey, and Gartner suggests that 70-95% of AI pilots do not deliver return on investment (ROI). Whilst they may function technically, they stall at the pilot stage, never scale, or produce outputs that the business cannot trust. Users quickly learn to double‑check or bypass the system, and adoption collapses. And it’s costing a lot of money. Abandoned projects typically result in $2–5M in lost production and opportunity costs.
The good news is that most failures are preventable. Organisations that treat AI as a long‑term capability, not a one‑off project, are already achieving sustained accuracy in the 95–99% range and strong ROI.
AI models don’t typically fail because of algorithms, design or poor code. They fail because of data, governance and mindset problems. Let’s look at each of these.
The #1 cause of AI failure: Data neglect
When it comes to AI projects, neglected data is almost always the biggest stumbling block. In fact, roughly 70% of AI failures are tied directly to data and training challenges. No matter how advanced your model or code is, if your data isn’t clean, organised, and properly prepared, your AI initiative is unlikely to succeed.
Many organisations overlook the basic data tasks of sorting, labelling, removing duplicates, annotating, and refining before modelling begins. They assume the model will “figure it out”, only to discover that the model has simply learned their historical noise, bias, and inconsistencies. They are often skipped as they can be labour-intensive, sometimes considered dull, and often expensive.
But smart budgeting in AI starts with the data pipeline. In ‘software 2.0’ (see later), data is the product, code is the supporting infrastructure. Instead of focusing your resources on model development, direct most of your time, money and effort into getting the data right. Here’s a practical breakdown of how your AI budget should look:
- 55–75%: Data collection, cleaning and annotation
- 10–20%: Monitoring and training
- 10–15%: Model development and coding
Most companies still adopt the 80:20 rule, putting the majority of spend into software development and code and only 20% into data work. This guarantees failure for AI projects and requires a mindset shift (see later). Practical signal for leaders: if your current AI budget shows “data work” as a small line item and “development” as the bulk, you are almost certainly under‑investing in the very thing that drives model quality.
| Tip: When training your AI model, train it on 80% of your data to get to an acceptable level of tolerance. Then use the remaining 20% to verify it and make sure bias hasn’t crept in. |
And remember, this is not a ‘one and done’. It is a continuous retraining process, always making sure you get to a probabilistic outcome and then keeping it maintained. If you don’t continuously retrain your AI, you can find it will drift and loose 30-40% accuracy even in as little time as six months. So continual investment is key.
This is where NashTech’s human‑in‑the‑loop (HITL) approach becomes critical, capturing real‑world errors, correcting them, and feeding them back into the training data so the model improves with every cycle, not just at annual release windows.
The #2 cause of AI failure: Mindset
For many organisations, the failure begins when people treat AI like a coding project rather than a data programme.
For ease, let’s assume there are two mindsets that people adopt:
- Traditional software thinking is the traditional language of programming. It has deterministic logic, whereby you write rules, and the system behaves predictably. It is developer-heavy, and the software will either work or it won't.
- AI thinking or ‘software 2.0’ is about probabilistic logic, whereby you train models and the outcomes are based on likelihood, not certainty. Data is at the core of the model.
|
Traditional software thinking |
AI thinking (software 2.0) |
|
Code is the product |
Data is the product |
|
Developers are central |
Data owners and domain experts are critical |
|
Build once, maintain occasionally |
Continuous learning and retraining |
|
Works or it doesn’t |
Accuracy exists on a spectrum |
Trying to apply traditional software thinking to AI programmes is stifling projects. Instead, the realisation that coding practices are evolving, with teams now having to share responsibility for their environments and transferring certain tasks to other groups, such as data teams, requires a shift in thinking. For CIOs and CTOs, the mindset shift is simple to state but hard to live: stop asking “Which model should we buy?” first, and start asking “How will we build and maintain the training data and feedback loops that make any model valuable?”
The #3 cause of AI failure: Governance
The single most important enabler of AI continuity is having a senior data owner. This is a chief data person or someone senior enough in the business that data is their main job for AI continuity. Someone ultimately accountable for:
- Data quality
- Data lifecycle
- Governance
- Integration with business processes
In practice, that ownership needs to translate into a clear operating model:
- Defined accountability: A named senior owner (CDO, CAIO, or equivalent) responsible for keeping AI systems within agreed accuracy, risk and compliance thresholds.
- Standards and policies: Documented standards for labelling, retention, access control, and bias mitigation, applied consistently across all AI initiatives, not rewritten for each pilot.
- Approval and escalation paths: Clear criteria for when a model can go live, when it must be rolled back and how incidents (e.g. harmful or non‑compliant outputs) are handled.
- Integrated into BAU: AI governance embedded into existing risk, audit, and change‑management processes, so models are treated like other critical systems, not experiments on the side.
Without this level of governance, organisations tend to deploy once, then quietly abandon models when performance or risk becomes uncomfortable, which is exactly the failure pattern we are trying to avoid.
Whilst these three common causes of failure are present in many projects, there are some businesses leading the charge.
Organisations excelling in AI implementation
There are numerous examples of organisations that are leading the way in their approach to AI. Companies such as Tesla, OpenAI, and Netflix share several key characteristics that underpin successful AI integration, including:
- Continuous data collection: These organisations maintain an ongoing process of gathering data, ensuring their AI systems remain relevant and effective.
- Ongoing retraining: Regular updates and retraining of models allow these organisations to adapt to new information and changing environments.
- Emphasis on feedback loops: There is a significant focus on establishing robust feedback mechanisms, enabling systems to learn from outcomes and improve over time.
- Deep integration into operations: AI is not a standalone feature but is intricately woven into the day-to-day operations, maximising its impact across the business.
It’s no secret that these organisations invest considerable resources to ensure their AI initiatives succeed. In some instances, businesses are allocating tens of billions of dollars, recognising that training data is a strategic asset that is uniquely theirs. While algorithms may be widely available, your proprietary data is not, and it serves as a key differentiator, helping to justify such a substantial investment.
However, pursuing AI excellence is not limited to those with deep pockets and vast resources. Organisations can target projects and develop their own capabilities without incurring the astronomical costs faced by industry pioneers.
Getting started with AI projects
Before launching into any AI initiative, it’s crucial to understand where your organisation sits on the AI maturity spectrum. This self-awareness helps set realistic expectations and guides your approach. Generally, there are three levels of AI maturity:
Three Levels of AI Maturity
|
Level |
Description |
Typical accuracy |
Risk profile |
|
Level 1 |
Out-of-the-box models, not trained on your organisation’s data |
60–70% |
High risk, low alignment with business needs |
|
Level 2 |
Models fine-tuned using your enterprise data |
80–90% |
Suitable for many practical applications |
|
Level 3 |
Continuous learning and refinement using ongoing data |
95%+ |
Strategic, scalable AI with lower risk |
Level 1 is where most organisations begin, relying on standard models such as ChatGPT or Copilot that aren’t adapted to your specific data. While these models can be helpful for routine administrative tasks, their accuracy is typically around 60–70%, meaning they’re unlikely to deliver meaningful business differentiation.
Level 2 takes things a step further by introducing your own data to fine-tune large language models. This approach often yields an accuracy of 80–90%, making AI much more useful and relevant for both your business and customers.
Level 3 represents the pinnacle of AI maturity, where systems are continually updated and refined as new data becomes available. This enables accuracy rates above 95%, with some organisations, such as NashTech clients, achieving as high as 99%.
However, it’s important to recognise that not every scenario requires such high levels of precision. Achieving these standards can be expensive and demanding, and the leap from 70% to 95% accuracy often requires substantial effort. Ultimately, the required accuracy depends on the nature of your business, customer expectations, and the risks involved.
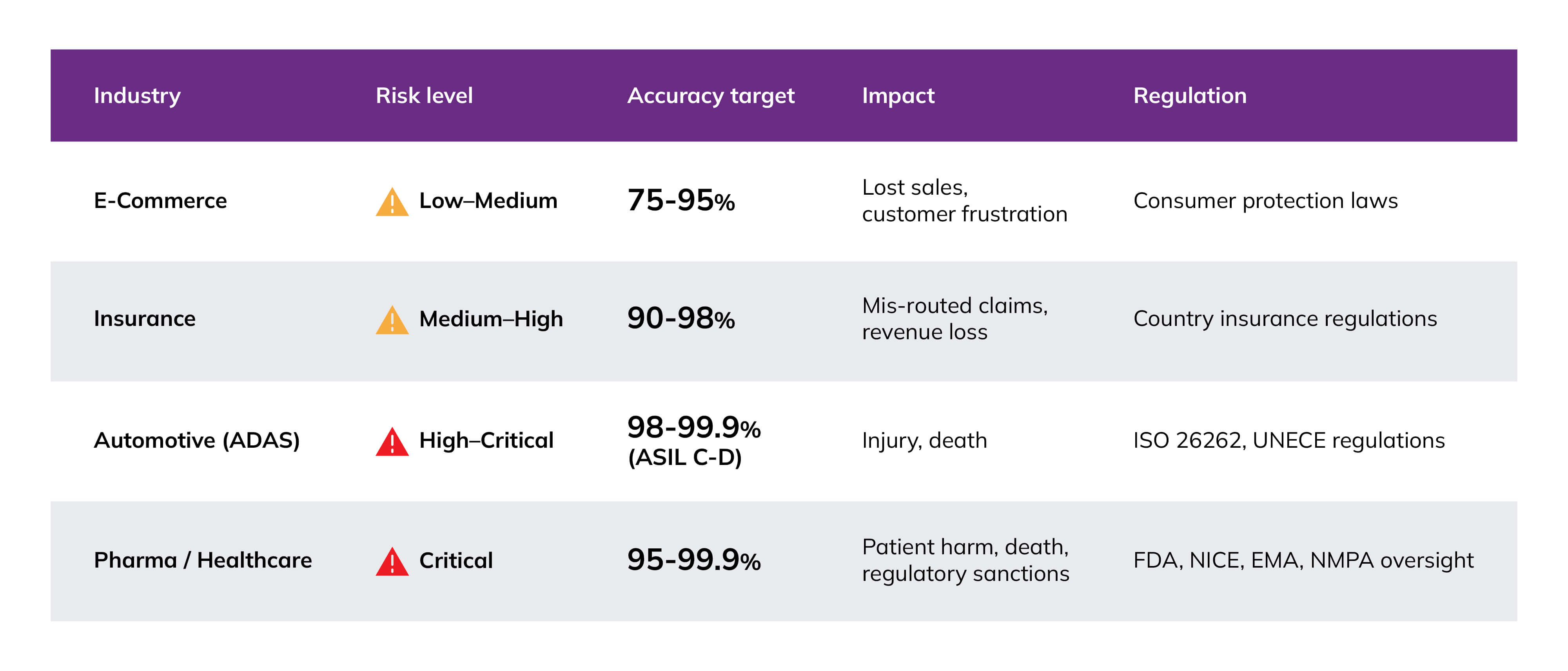
For instance, in the automotive sector, the tolerance for error is extremely low; if you’re trusting AI with control of a vehicle, you want near-absolute certainty that it will operate safely. By contrast, showing an online shopper the wrong item, say, a black skirt instead of black trousers, it is an inconvenience. The level of accuracy you target should reflect the potential impact on customer experience, any regulatory requirements, and the safety implications of your AI application.
For leaders, two questions matter most: “What accuracy do we truly need for this use case?” and “What governance and human oversight are in place when the model is wrong?” Clear answers to these questions turn abstract maturity levels into actionable investment decisions.
If you would like industry‑specific benchmarks (e.g. retail vs. healthcare vs. financial services), NashTech can provide typical target ranges and risk assumptions drawn from current client work
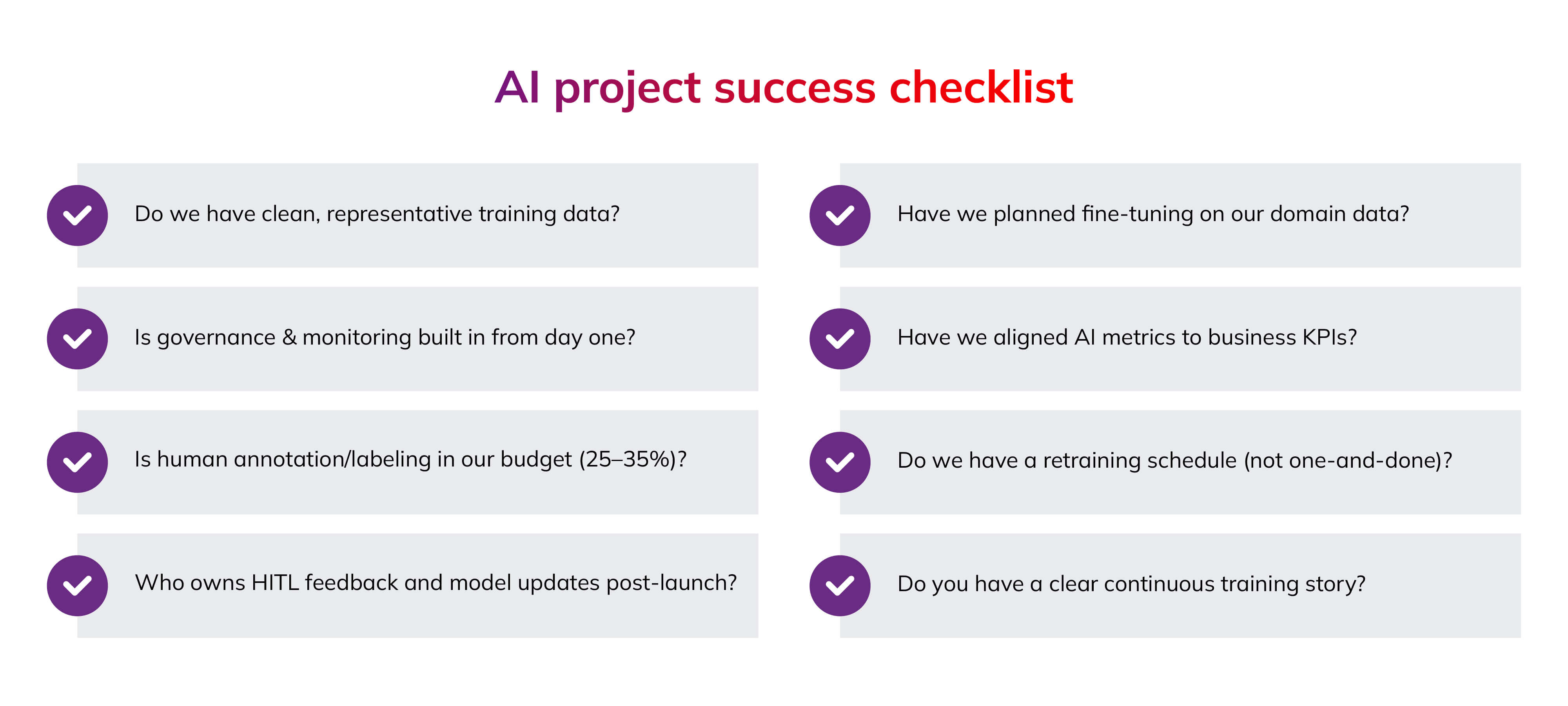
Your AI checklist
It’s worth emphasising that AI failure is common, but rarely random. With the right structure, strong leadership, and disciplined data management, organisations can transition AI from a risky trial to a dependable business asset. To help set your AI initiative on a path to success, we’ve put together a straightforward checklist for managing AI projects effectively. You can use these bullets as a pre‑implementation gate: if you cannot confidently tick each item, delay the project, fix the gap, and then proceed.
Key takeaways
Successful AI depends on strong data foundations and clear business goals. Before starting, confirm that your challenge is fit for AI and that your data is up to the task. If your data is lacking, you’ll need to build it first, even if that adds complexity.
Deploy AI carefully: start with a small, controlled rollout and test thoroughly before scaling up. This makes broader adoption smoother and reduces risk.
AI requires ongoing attention. Models lose accuracy over time, sometimes in just six months, so keep updating and improving them to maintain value.
Essential guidelines for CIOs and CTOs
- Data comes first
- Budget for training, not just modelling
- Keep humans involved, always
- Design for ongoing improvement
- Align accuracy with risk
- Assign clear data ownership
- Treat AI as a living system, not a one-off project
|
With over 17 years of hands-on experience in deploying and training AI and machine learning solutions with leading global hyperscalers, NashTech has established a proven framework that identifies effective strategies, highlights common mistakes and their underlying causes, and offers practical guidance for successful implementation. |

About the author
David Thorley serves as the Global Annuity Services Director at NashTech, bringing with him an impressive background in artificial intelligence and machine learning. With over twenty years of experience in the field and six years dedicated specifically to AI, David’s expertise spans both the strategic and technical aspects of emerging technologies. His leadership and insight are instrumental in guiding organisations through the complexities of AI implementation and innovation.
Suggested articles


.jpg)